Yet Another Note On Skewness And Kurtosis
Due to a project I recently work on, I would like to know the relationship between skewness and kurtosis. After some Google search, I am directed to Wilkins’s paper : A Note On Skewness And Kurtosis [PDF] in which he gave an new proof of the following inequality:
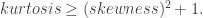
However, he only proved it for random variables with finite values. It’s quite natural to extend his proof to any real-valued random variable. Here is the proof I give only involving fundamental concept and definition from probability theory and quadratic form which is exactly the remarkable idea from Wilkins’s original proof.
Let 
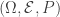


Also, denote the 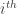
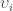
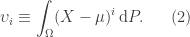
And, the standard deviation 

Define the 
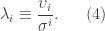
Here, 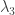
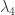

and

Now, consider the quadratic form
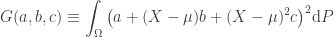
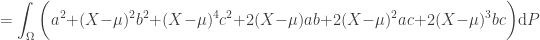
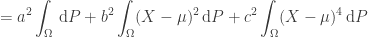
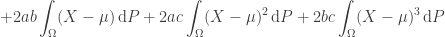

Since 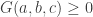
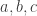


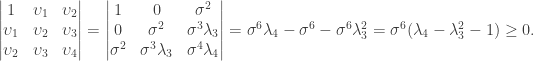
For any real-valued random variable whose standard deviation is not zero, we have

Note that standard deviation 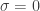

Well done. Just note a type error that is the last term in the matrix should be lambda4*sigma^4
Thanks! It is corrected now.