1. Introduction
A positive integer is called  -smooth if none of its prime factors are greater than . Let
-smooth if none of its prime factors are greater than . Let  be the set of prime numbers not greater than , i.e.,
be the set of prime numbers not greater than , i.e.,

In the classic Hamming problem, we are asked to print the first 
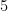 -smooth numbers (they are also called Hamming numbers) in the increasing order. Dijkstra [1] proposed the algorithm below in 1981 to solve this problem.
-smooth numbers (they are also called Hamming numbers) in the increasing order. Dijkstra [1] proposed the algorithm below in 1981 to solve this problem.
Dijstra’s Algorithm
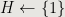 ,
, 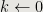 ,
, 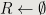
while 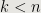
 .
.
 (
(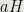 means the set
means the set  )
)
Put  into
into 

endwhile
Although Dijkstra’s algorithm is designed to solve the classic Hamming problem, it is quite straightforward to extend it to solve general Hamming problem, i.e., print the first -smooth number in the increasing order. However, the programming language without lazy evaluation feature, it is very hard to manage it to run in  time, provided that computing multiplication of two integers takes
time, provided that computing multiplication of two integers takes  time. In this paper, we propose a new algorithm to solve Hamming problem in a more general setting described below.
time. In this paper, we propose a new algorithm to solve Hamming problem in a more general setting described below.
Let  be a finite set of
be a finite set of  positive integers. We arrange the elements in so that
positive integers. We arrange the elements in so that 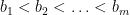 . We say that is a smooth base if for each element
. We say that is a smooth base if for each element  , it has a prime factor
, it has a prime factor  whose is not included in any other element. Formally, is a smooth base if and only if
whose is not included in any other element. Formally, is a smooth base if and only if

where  means there is a integer
means there is a integer  such that
such that  , and
, and 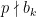 means no such integer exsits. Such a prime factor is called the key factor of . In other words, is a smooth base if and only if every element has at least one key factor.
means no such integer exsits. Such a prime factor is called the key factor of . In other words, is a smooth base if and only if every element has at least one key factor.
Given a smooth base  , we use
, we use  to denote the set containing all the integers in the form
to denote the set containing all the integers in the form
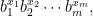
where  are nonnegative integers. We also say that is generated by , and numbers in are called generalized Hamming numbers. It is easy to see that every number in can be uniquely represented by this way, i.e., every number in correpsonds to a unique tupple
are nonnegative integers. We also say that is generated by , and numbers in are called generalized Hamming numbers. It is easy to see that every number in can be uniquely represented by this way, i.e., every number in correpsonds to a unique tupple 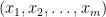 . Thus, once the smooth base is fixed, we also simply use to denote
. Thus, once the smooth base is fixed, we also simply use to denote 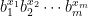 .
.
Note that is a smooth base for all 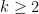 . For example, if
. For example, if 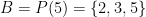 , then is the collection of all -smooth numbers. Thus, computing the first -smooth numbers is just a special case of computing first generalized Hamming numbers generated by a smooth given smooth base.
, then is the collection of all -smooth numbers. Thus, computing the first -smooth numbers is just a special case of computing first generalized Hamming numbers generated by a smooth given smooth base.
2. Algorithm
Examinating the Dijkstra’s algorithm closely, we can see that there are two essential operations: finding the minimum of  and merging
and merging  ,
, 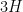 and
and  . For the merging operation, if the three components merged are disjoint, then it is very easy. Unfortunately, they are not. For example,
. For the merging operation, if the three components merged are disjoint, then it is very easy. Unfortunately, they are not. For example,  belong to and for
belong to and for  . To avoid such duplicating, one possible way is to resolve the ambiguity: assign to either or , but not both. This can be done by adopting a kind of “Maximum Principle”: if
. To avoid such duplicating, one possible way is to resolve the ambiguity: assign to either or , but not both. This can be done by adopting a kind of “Maximum Principle”: if  and
and  at the same time, and
at the same time, and  , we only assign
, we only assign  to
to  . For belongs to more than two such sets
. For belongs to more than two such sets 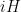 , we assign to the one with largest
, we assign to the one with largest  . Inspired by this idea, we have following algorithm to compute first generalized Hamming numbers generated by a smooth base .
. Inspired by this idea, we have following algorithm to compute first generalized Hamming numbers generated by a smooth base .
k-Smooth Algorithm
Initialize queues  to be empty
to be empty
for 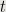 from
from  to
to 
push  into queue
into queue 
endfor
while do
Let be the minimum element in the front of each queue  and assume
and assume 
for from  to
to
push  into queue
into queue
endfor
Remove from  .
.
Put into output sequence
endwhile
Theorem 1: When k-Smooth Algorithm terminates, is the sequence of the first  generalized Hamming numbers generated by
generalized Hamming numbers generated by 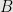 .
.
To prove the theorem, we shall firstly establish two impartant facts. The first one shows that  and
and 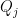 are disjoint if
are disjoint if  .
.
Fact 1: If  , then
, then 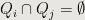 .
.
Proof: We first show by induction that any element in  does not contain any key factors of
does not contain any key factors of  . At the beginning,
. At the beginning,  and by the definition of smooth base ,
and by the definition of smooth base , 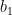 does not have key factors of . Now assume after the first
does not have key factors of . Now assume after the first  loops of the while block, elements in do not contain key factors of . If at the
loops of the while block, elements in do not contain key factors of . If at the  st loop of the while block, a new element
st loop of the while block, a new element  is pushed into , then according to the algorithm,
is pushed into , then according to the algorithm,  must come from and hence does not contain key factors of . This also implies that does not contain key factors of and all members of do not contain key factors of in the end of the st loop. The statement is trivially true if there is no element pushed into in st loop.
must come from and hence does not contain key factors of . This also implies that does not contain key factors of and all members of do not contain key factors of in the end of the st loop. The statement is trivially true if there is no element pushed into in st loop.
Again, by induction we show that members in (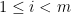 ) do not contain key factors in
) do not contain key factors in 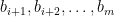 . For
. For 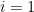 , the statement holds by the argument above. Now assume the statement holds for all
, the statement holds by the argument above. Now assume the statement holds for all  . By the similar argument used to prove the statement for , we can show that the statement also holds for
. By the similar argument used to prove the statement for , we can show that the statement also holds for 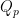 . Therefore, the statement holds for .
. Therefore, the statement holds for .
By the algorithm, we also know that elements in 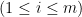 includes key factor of
includes key factor of 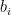 . Now let
. Now let  . Since members in do not contain any key factor of
. Since members in do not contain any key factor of 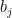 while all members in have a key factor of , no element in can belong to and hence
while all members in have a key factor of , no element in can belong to and hence  .
. 
Now we have known that elements from different queues are distinct. To demonstrate that no duplicated numbers will be added to  , we need to show that elements in the same queue is also distinct. Actually, we manage to show a stronger conclusion: elements in the same queue are pushed into the queue by the strictly increasing order. We also obtain an important fact at the same time, which shows every generalized Hamming number will be pushed into some queue. This guranttees than no generalized Hamming numbers are skipped by the algorithm.
, we need to show that elements in the same queue is also distinct. Actually, we manage to show a stronger conclusion: elements in the same queue are pushed into the queue by the strictly increasing order. We also obtain an important fact at the same time, which shows every generalized Hamming number will be pushed into some queue. This guranttees than no generalized Hamming numbers are skipped by the algorithm.
Before starting the next fact, we define followers of a generalized Hamming number as the numbers  .
.
Fact 2: At any time, elements in 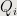 (
(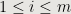 ) are strictly increasing and hence distinct. Also, if at step
) are strictly increasing and hence distinct. Also, if at step  ,
,  is removed from some queue, then each of its followers, either has been already pushed into some queue at some step
is removed from some queue, then each of its followers, either has been already pushed into some queue at some step 
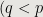 ), or will be pushed into some queue at the step .
), or will be pushed into some queue at the step .
Proof: Again, we prove it by induction. Obviously, at the very beginning of the first loop of the while block, the statement above holds. Assume the statement is correct at the step 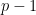 . Suppose at the step ,
. Suppose at the step , 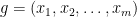 is removed from queue .
is removed from queue .
For 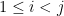 , since
, since 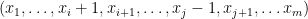 is smaller than
is smaller than  , it was removed at some step
, it was removed at some step 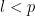 , according to the induction assumption. Therefore, by the assumption, its follower
, according to the induction assumption. Therefore, by the assumption, its follower  , which is also a follower of , was pushed into some queue before the step . For
, which is also a follower of , was pushed into some queue before the step . For  , the follower
, the follower  is pushed into at the step . Therefore, the second half of the statement still holds for the step .
is pushed into at the step . Therefore, the second half of the statement still holds for the step .
For each such that  , there is a new element pushed into . If contains only one element , then is increasing trivially. Now assume contains more than one element. Let
, there is a new element pushed into . If contains only one element , then is increasing trivially. Now assume contains more than one element. Let  be any one in other than . According to the algorithm,
be any one in other than . According to the algorithm,  was pushed into before because the element
was pushed into before because the element 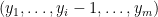 was removed from some queue before . Hence
was removed from some queue before . Hence  , and further
, and further  . That is,
. That is,  , and is strictly increasing.
, and is strictly increasing.
Given these two facts established, it is quite straightforward to see the correctness of the statement in Theorem 1.
Proof: Since numbers in each queue is strictly increasing and numbers in all queues are distinct, the outputed sequence is strictly increasing and hence has no duplicates. Also, since no number will be skipped, the output sequence must contain the first generalized Hamming numbers generated by the base when the algorithm terminates.
A PDF version of this article can be found here.
References
[1] Edsger W. Dijkstra. Hamming’s exercise in sasl. 1981.
